

Data, Algorithms, and Ethics: Calculating instead of deciding
Backgrounder
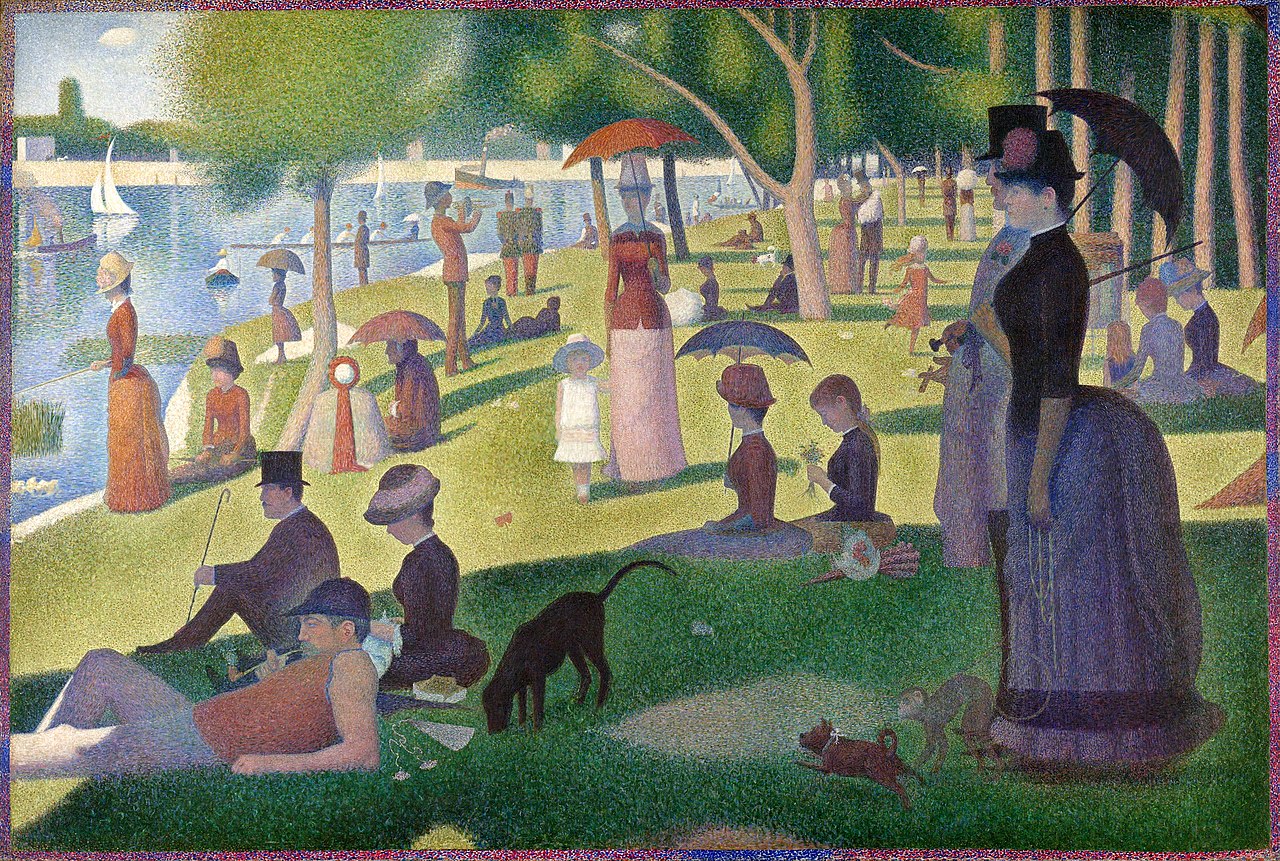
Share this Post
Data and Algorithms
“Under the modern conditions of data processing, the free development of personality presupposes the protection of the individual against the unlimited collection, storage, use and disclosure of his or her personal data.” This was formulated by the German Federal Constitutional Court (BVerfG) as early as 1983, ten years before the World Wide Web, twenty years before Facebook, thirty years before the revelations of Edward Snowden and almost forty years before the infamous leak of Israel’s full voter register in 2020. This universal right to informational self-determination has lost none of its significance – on the contrary. To exercise this right accordingly, we, as responsible and educated citizens of the information society, have to become conversant in technical terms like data and algorithms. We do that easily nowadays, but we should also deeply understand them to see the chances and assess the risks incurred by their use. What are data, what are algorithms, and what is this artificial intelligence everyone is writing into research grant applications right now? This topic is so important because data now determines the weal and woe of everyone on this planet. More precisely, it is important because it is a privileged few who have the informational power to use this data according to their own advantage – at the expense of others. Data and algorithms have left the innocent sphere of scientific discovery, and now determine human actions and decisions. They have thus become the subject of ethics, a matter examined more in depth elsewhere (see Ullrich 2019).
In what follows, we will follow the flow of data together, from the emergence of the term data to the development of data processing technology and today’s ethical considerations in a global data-driven business ecosystem. Prior knowledge of what data are and how they are created is not necessary for understanding this text. On the contrary, it is technical experts who have striking gaps in their knowledge of the socio-technical context.
Data comes from the Latin word for “that which is given.” One of the founders of modern science, Francis Bacon (1561-1626) called his written observations of nature “data.” Indeed, that is what data is in a nutshell: The scientific mind observes or measures its surroundings and records the findings. Of course, in the computer age we strive for machine-readable data coded in a way that a mindless machine can process. The first step, therefore, is to transform the observed phenomena into a discrete and automatically processable form. Let’s take for example a sung or played note. An acoustic wave is continuous, like a hand-drawn curved line on paper. If we want to record that continuous wave, we have two options: We can use an analogue method (audio cassettes, magnetic tapes, vinyl) or we can use a digital recording device. Inside, there is a so-called analogue-to-digital converter that works pretty much like us trying to create an image with ironing beads. Ironing beads are small cylinders of plastic that are placed on a grid to form a picture and then ironed so that the individual plastic pieces combine to make a great gift for, say, grandparents. Digitalization is a similar process, in that it requires a grid as an overlay for an analogue figure. Imagine a piece of graph paper on which you draw a wave. Now, in your mind, or with the help of an actual piece of graph paper and a pen, color in all the boxes through which this wave passes. You can then save the discrete data version of the wave digitally and in binary: Enter a zero for each white box and a one for each colored box. Of course, the digital data is only an approximation of the original wave, but you can use a smaller grid if you want greater precision. Don’t bother too much though; we humans have brilliant processing qualities and can recognize or more precisely reconstruct the original wave (this is what happens when we listen to compressed audio files).
Now that we have data – what can be done with it? We can interpret it and write down our interpretations as facts in the original Latin sense of “that which is made.” If we are using scientific methods, we write down our intention, our observation setting, our data, the methods that we apply in order to draw conclusions, and the conclusions themselves. Somewhat reluctantly, we then invite our fellow colleagues to take a critical look at our results. So, yes, there are “alternative facts,” but not all of them are scientifically derived. Francis Bacon insisted that there is an essential difference between data and facts. What both have in common is that they can be symbolically noted in pictures, words, and numbers. The number, however, is something special; it can be used not only for counting, i.e. for recording, but also for calculating. Focusing only on the European Renaissance (a bias I share with many of my colleagues from Europe), it is striking to see that in modern times everything became a calculable number. Renaissance merchants discover this added value of calculability when they began to employ the then-new and modern Arabic numerals, including the incredible zero, in place of the Roman numerals that were common at the time. In addition to Arabic numerals, they used a simple and ingenious scheme: the table. They were then able to save what they had thus calculated and to share this information with their colleagues. Science, when it was less dependent on third-party funding and the spreadsheets that come with it, also used the table enthusiastically. The first row usually contains designations, such as measured quantities and units, while subsequent rows include symbols, writing and – above all – numbers. Gottfried Wilhelm Leibniz (1646-1716) eloquently described the power of the table to his sovereign using as an example its utility given the busy mind of the ruler who could not possibly know how much woolen cloth is manufactured in which factories and what quantity is demanded by whom in the population. Since knowledge of this “connection of things” is essential for good government, he proposed so-called “government tables” (Staatstafeln), which make complex facts comprehensible at a glance and thus governable and controllable (Leibniz 1685). Leibniz went even one step further. Wouldn’t it be great, he mused, if we could actually calculate the result of a debate instead of exchanging arguments? Calculemus – let us calculate! What Leibniz originally offered as a tongue-in-cheek suggestion began to resonate increasingly with his enlightened spirit looking at a complex world. Data could soothe the spirit, function as a toolbox for answering pressing questions about life, the universe, and all the rest. Will there be sun after the night? Will there be another spring after this winter? By collecting data in the course of several years, patterns might emerge, leading to a hypothesis by presenting correlations that could show the way towards an unknown cause. Data is a powerful tool, but like all tools it is to be handled with expertise and care. Feeding data to a data mining or machine learning system can provide a clue as to where to look further – but this clue is not a fact; it is another type of data: algorithm-generated data. Before we continue, we have to explain what an algorithm is.
Algorithms are codified prescriptions for mathematical problems that can be processed by a human mind. Algorithms are thus primarily techniques of instrumental reason. The oldest example of an algorithm is one you probably learned in school: Euclid’s algorithm for determining the greatest common divisor. Given two positive integers a and b such that a is greater than b, we calculate the greatest common divisor gcd(a,b) by calculating gcd(a-b, b), replacing the larger number by the difference of the numbers, and repeating this until the two numbers are equal – that is the greatest common divisor.
Algorithmic data processing provides results that are not yet directly visible in the data itself, like a common divisor hidden in a pair of numbers. An algorithm cannot tell the Minotaur where the exit is, but it can tell it how to find the exit, guaranteed. A possible algorithm would be: “Always feel your way along the right wall, follow every corridor that leads off to the right. If you meet a wall head-on, turn left so that that wall is now on your right. Keep going until you come to an exit”. The power of algorithms is today most evident thanks to the availability of huge amounts of data (“big data”) and a new tool called “machine learning.”
Machine Learning
“Definition: A computer program is said to learn [original emphasis] from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.” (Mitchell 1997, p.2)
This canonical definition of machine learning is found right on the second page of Tom Mitchell’s widely cited standard work on the subject. It is very easy to read, but it is not easy to understand what “experience” means when applied to a machine. I’ve been pondering for a long time with my colleagues at the Weizenbaum Institute about how we can explain machine learning to a broad audience without too many formulas and at the same time avoid over-simplifying or anthropomorphizing. Our research turned up an article from 1961 that successfully overcomes this challenge.
MENACE was the name of a machine built by Donald Michie in the 1960s that could play Noughts and Crosses (also known as Tic-Tac-Toe, Three in a Line, or Tatetí) against a human player (Michie 1961). The Machine Educable Noughts And Crosses Engine was a machine learning system but with a twist: The machine was made of matchboxes filled with colored beads. The setup was quite impressive – no less than 304 boxes are needed, one box for each possible configuration during the game. The operator of MENACE makes the first move by picking a matchbox labelled with an empty playing field, shaking it, and drawing a colored bead. Each color represents one of the nine possible positions an X or an O can take on the playing field. In the course of the first games the machine will likely lose, because the beads are drawn randomly. Enter the machine learning part: If MENACE loses, the operator will remove all the drawn beads that lead to defeat. If MENACE wins, the operator will add three beads of the drawn beads in each picked box. That means that the chance of losing again will be reduced while on the other side good moves are rewarded considerably. Trained long enough, MENACE will “learn” a winning strategy (by improving the chances of good moves) and therefore will “play” pretty well.

Picture A recreation of MENACE built by Matthew scroggs / Wikimedia Commons
{kind=link}
The interesting part is that no human player would ascribe any intention or other cognitive ability to a pile of boxes in contrast to machine learning systems implemented by way of software on computer hardware. False and anthropomorphic ascriptions are quite normal with computers in general and artificial intelligence in particular. Joseph Weizenbaum, a critical observer of the information society, was puzzled by the “enormously exaggerated attributions an even well-educated audience is capable of making, even strives to make, to a technology it does not understand.” (Weizenbaum 1976, p.7) False attributions often stem from common narratives and metaphors that help us to understand complex issues, but it is better to describe how things work simply and correctly at the same time.
MENACE is not a metaphor for a machine learning system, it is a machine learning system. Of course, there are much more sophisticated machine learning systems out there, but all have one thing in common: They were designed and created by human beings with a purpose and applied in a specific domain. Outside that domain or used for any other purpose, these systems are useless (in non-critical contexts) or harmful (if used for sovereign tasks). So, MENACE is a good way of thinking about the use of decision-making systems: Do you want a pile of matchboxes to “decide” what you wear today? Probably; I mean, why not? But do you want a pile of matchboxes “decide” whether you will give a job to someone? Definitively not.
Assisted Decisions
We all know situations in which we cannot make up our minds. In 19th-century France, a person unable to predict a romantic situation might pick the petals off a daisy one by one, reciting: “Elle/il m’aime, un peu, beaucoup, passionnément, à la folie, plus que tout, pas du tout.”. It is, of course, complete folly to believe that a flower can tell us anything about another person’s state of mind or about anything in the world. Nevertheless, the very process of grappling with uncertainty helps us gain clarity about ourselves. “If you want to know something and cannot find it through meditation,” Heinrich von Kleist advised in 1878, “you, my dear, sensible friend, must talk about it with the next acquaintance who bumps into you. It need not be a sharp-thinking head, nor do I mean it as if you should ask him about it, no! Rather, you should tell him yourself first.” A flower is not known to be a sharp thinker, but it serves the purpose of standing in as a sounding board. As a computer scientist, I am irritated that the computer is thought to have more thinking capabilities than the daisy. This is not the case. On the contrary, in a direct comparison the plant would win hands down. It is the lack of knowledge about the nature of daisies and computers that makes outsourced decisions so problematic. A daisy usually has 34 petals, so the person consulting with this oracle always receives affirmation that he or she is loved beyond measure (“plus que tout”). Even with binary questions that have a “yes” or “no” answer, the answer comes out as “yes” with most flowers: Snowdrops have 3 petals, buttercups 5, 13 crown the calendula, asters have 21 – only larkspur (delphinium) gives us a “no,” but what might we expect from such a poisonous plant?
Whether with plants or computers, the structure must be deeply understood. If I am to be honest, I have no idea whether the number of petals of the plants described above really adhere to the mathematical Fibonacci sequence – but I know why that should be the case: The highest density on the stem is obtained when the angle between two successive primordia is 137.5°. This so-called “golden angle” results when the plant forms its structures exactly according to the Fibonacci sequence. The plant does not roll the dice, it optimizes its growth. Let us leave the realm of natural oracles and move towards its modern variant: computer-aided decisions.
Calculating instead of Deciding – Automated Edition
Several centuries after Leibniz proposed his idea of calculating the results of an argument, it is software companies that are using a similar pitch to sell their products. Wouldn’t it be nice if we could calculate the best outcome of a decision we face? One might think that with a universal decision-making system, we would be able to calculate not only which of us is right in the event of a disagreement, but also determine with certainty who is the best fit for our company. We would no longer have to decide – we’d simply calculate. What’s more: Even for things we don’t sufficiently understand, we could simply calculate the right answer. The pitch was very successful: In the more than three hundred years since Leibniz, this mindset has become firmly embedded in our scientific methods. Calculating relieves us of the responsibility of making decisions, and has the benefit of being faster and cheaper. There is a categorical difference between calculating or deciding. A calculation is a mechanical process according to certain rules, a decision is a very reflective process that involves not only logic but also the whole being of the decision-maker – and ignoring that is a problem.
An algorithmic decision system is not simply a technical system but also and foremost a socio-technical system. It consists of at least two subsystems: The information technology (IT) system and the human beings involved. IT systems cannot decide – they can only calculate. Human beings operating the systems decide. Admittedly, they do so as part of a complex process in which data has been processed and classified. At the end of this process, in most cases, there is a number that can be read off an interface. But it is not a decision.
This number provides a measure of security, safety, control. However, it misleadingly suggests a certainty that no IT system has. This is because of the limits of discretizing. People, using various tools, discretize their continuous environment and note their observations in symbolic form (as described above in detail). The data is then entered into the digital computer. This process of discretizing and its problems can be demonstrated very well using a famous painting. Perhaps you know George Seurat’s famous work “Un dimanche après-midi à l’Île de la Grande Jatte,” which is a work of pointillism. In this painting technique, the transitions between the areas of color appear to be fluid even though they are the result of very precisely placed dots on a canvas. For example, looking at a painted tree and placing my index finger along the edges, it is difficult to discern: Does the dot right under my finger still belong to the tree or already to the sky? Our brain draws a symbolic line where there is none in the physical world. That is one of the many messages of pointillism: There are no lines in nature; it is we who draw them.
We also draw such lines in software systems that are supposed to classify something. Given a point/dot/pixel, the software “decides” whether it is “tree” or “sky.” Maybe it measures the frequency of the color and spits out a number, 490 nanometers for instance. Is that still blue? Or already green? Instead of the result blue or green, the software should print out the confidence interval: Could be blue, could be green – you decide! This points to another basic assumption that is rarely talked about. The IT system does not classify tree/sky, but green/blue, or 490/480 nanometers. Nevertheless, a tree at sunset or in autumn is recognized by humans as a tree, even without looking carefully, because we do not pay attention (only) to the colors of the leaves but recognize its “treeness,” its arboreality. This ability is innate to us, but we cannot fully explain it, let alone reproduce it.
If we give up this absolute idea of true/false and work only with probabilities and statistics, classification works surprisingly well in most cases. Is that a tree? It’s big, brown on the bottom, green on top, and all the people and bots on Twitter say it’s a tree – then it probably is a tree. This approach is sufficient for the reality of our lives, and this is precisely the strength of heuristic as opposed to algorithmic computer science systems: They can deal with little data, with a lot of data, with accurate data, with inaccurate or even contradictory data – and deliver a result that is approximately true.
e are currently experiencing nothing less than a heuristic revolution. We no longer compute using algorithms; rather, we train a system that works heuristically. Old and busted: Truth. New and cutting-edge: Sufficiency.
Last year, the German federal government commissioned an expert opinion for the Third Report on Gender Equality, which was to carry out a detailed examination of the functioning of recruiting systems. It was difficult for the commissioned experts to understand exactly how it worked because the products that are in use were proprietary and not open source and therefore an elaborate black box study would have had to be carried out to investigate the discriminatory effects of these systems. Pending such a study, we might attempt to understand how automated decision systems work based on biometrics.
Biometrics, i.e. the measurement of life, is an instrument of statistics. Biometric systems are heuristic systems that use sensory data and a knowledge base, including mortality tables, age structure of the population and average life expectancy. These data are of interest to state leaders when it comes to taxes, participation, and distribution of common goods. In one of the first scientific works on biometry, the Swiss natural scientist Christoph Bernoulli described how a table of life expectancy should be structured and what advantages arise from this clear connection of things. Bernoulli also made clear who commissioned the acquisition of said data: it was life insurance institutions that made the collection of this data “a necessity” (Bernoulli 1841, pp.398-399). Once the transdisciplinary cultural technology researcher has picked up this techno-historical trail, she discovers the true motivations behind biometric systems everywhere (following Knaut, 2017). Since Francis Galton, biometrics, beginning with dactyloscopy, has not only served law enforcement purposes, but also, voluntarily or involuntarily, support racist mindsets and practices. There are numerous examples of this, from facial recognition systems that only work adequately on white faces to smart soap dispensers that only soap up white hands: In 2017, Chukwuemeka Afigbo shared a video on Twitter showing two people trying to use an automatic soap dispenser. After the first person picked up his portion of soap, a second person with dark skin put his hand under the dispenser and nothing happened. Then he took a white napkin and the sensor recognised the hand. Both people in the video laugh, it amuses them, but it shows a very serious problem.
Fortunately, this behaviour is no longer a selling point as it was in the heyday of eugenics. Biometric recognition systems are usually marketed as access systems (verification of people) or generally as official security technology (identification of people). The introduction of biometric passports and ID cards in Germany (in 2003) and Israel (in 2013) were also presented from this point of view. However, the data-based business models of biometric recognition systems have a built in marketing limitation: they technically fall under the General Data Protection Regulation (Article 9 (1) GDPR), which makes exploitation at least on the European market challenging. Biometric data is also the most intimate and visible data: Unless there is a pandemic, we are constantly showing our faces. And even in Corona times, we can be identified in a crowd despite the mask due to particularities of our gait. On closer inspection, however, it is not true that an identification is made, but rather that an identity is attributed.
Attribution is the exercise of informational power. A privileged few can impose an assessment of many data subjects. This can be shown most vividly in the debate about parole board decisions. In most countries, prisons serve not only to protect the general public from convicted criminals but also to reintegrate these same criminals into society after they have served their sentences. In the case of suspended sentences, a review is carried out to determine whether the prisoner can be released on parole. In Germany, this decision is rendered by a court, which has to make a prognosis and decide whether it can be assumed that the offender will not commit any future crimes even without completing the original prison sentence. The suspended sentence is based on the convicted person’s right to resocialization in accordance with the constitution. In U.S. law, the decision is made by a parole board within the state government, which takes into account conduct in prison, the prospect of rehabilitation, and any continuing danger the convict may pose. Parole board members must meet high standards to adequately address both the fundamental rights of individuals and the rights of the community. They are usually judges, psychologists or criminologists, and are also specially trained in ethical issues. It is an immensely mentally demanding activity, and any help is therefore gladly accepted. As with Leibniz, experts are asking themselves: Wouldn’t it be wonderful if there were a number that gave out the risk score reflecting the potential of a new crime being committed by the person under consideration? Why yes, there is, at least for the United States of America. It is calculated as follows:
Violent Recidivism Risk Score = (age∗−w) + (age-at-first-arrest∗−w) + (history-of-violence*w) + (vocation-education∗w) + (history-of-noncompliance∗w)
The Practitioner’s Guide to the decision support tool named “Correctional Offender Management Profiling for Alternative Sanctions (COMPAS)” from 2015, explains that each item is multiplied by a weight (w) which is determined by the “strength of the item’s relationship to person offense recidivism that we observed in our study data” (Northpointe 2015, p.29). Even if you do not understand the underlying formula, you see immediately that the entire score depends on the convicted person’s past, and on a mysterious correction factor called “weight,” obtained via an obscure process protected by trade secrets. A parole board decision is a prognosis – yet it is achieved by means of the past so it should be called “postgnosis” instead. One of its biggest problems is that such systems are necessarily biased, simply because their underlying data are biased. Data are biased in a fundamental way: You can only measure what is measurable. You cannot measure future intentions of criminal minds (or any mind for that matter), but maybe there is a proxy datum that correlates very well with the unobservable. In statistics, there is the famous example of the positive correlation between appearance of storks and the number of new-born children. People in Europe were especially susceptible to attributing causality since they grew up on the Slavic myth that storks bring children into the world. Ultimately, we treat phenomena that correlate with existing data and fit the narrative as if there is a causal relationship. When we have heard often enough that women and children are rescued first in a shipwreck and then look at the data of the Titanic disaster, we see the maxim at work. Admittedly, with a different narrative, there is a better theory to fit the data: It was people on the upper decks who were saved in a greater number compared to people of the lower decks. This happened for the simple reason that there were many more lifeboats in the vicinity of the rich and powerful passengers. So, it is more accurate to say that the rich and powerful were rescued first – but that is an unpopular narrative.
Data sets in general are created to benefit groups that already have economic power over other groups for the simple reason that good data are expensive. Due to the investment required for data analysis and processing, you expect the data to pay back. There are types of incentives other than money, for example political and informational power. The main incentive of Luftdaten.info, to pick a well-known civic tech example from my country, was to collect environmental data to shape the public discourse about fine dust in Stuttgart (Germany). Before this project started, there were no data available to the public regarding this important environmental issue. That was no coincidence: The car manufacturers in Stuttgart have a combined annual revenue of 200 billion EUR – compare that to the .000002 billion EUR budget of Luftdaten. Nevertheless, we revealed in a recent study how this Civic IoT project, though being organized within limits of technical equipment, resources, and academic knowledge, contributed in multiple ways to more sustainable cities or communities (Hamm et al. 2021). This brings us to my final point.
Data Literacy and Empowerment
Data are essential for human control. This sentence can be read and interpreted in two ways. First, it can be understood as genetivus subjectivus: People use data to measure and therefore control their environment. In the age of surveillance capitalism (Zuboff 2019), however, the second meaning (genetivus objectivus) has also been debated: Data is used to control people.
I would like to conclude with a positive and constructive note regarding the use of data. Data are the key to knowledge; they are the basis of empirical sciences and offer a view of the world not only to quantitative but also to qualitative researchers. Data are not facts, as we learned from Francis Bacon, and we should always keep this in mind. Data can generate, confirm, or call into question facts in the scientific working mind. Data can also obscure facts. Data science is slowly maturing into the basic cultural technique of the responsible member of the networked society. Data scientist Hans Rosling demonstrated to a large audience on Youtube, vimeo and other social media how data can be used to bridge cultural differences, break down prejudices and ensure common understanding. In a very humorous and exposing way, Rosling holds a mirror up to us showing that we rely on obsolete data, wrong numbers, and biased facts that we learned in school and that are now reproduced on all media channels. Our conceptions of countries in the global South, for example, are closer to myth than to the present reality (Rosling 2006). Debunking false and even harmful assumptions was the main drive of Rosling the humanist. But for debunking to happen, the according data must be available. This depends on instruments and tools, but it also depends on culture and customs. It is not because of a lack of tools that Caroline Criado Perez (2019) observed a Gender Data Gap, but also because of the data culture of the majority society. Data is collected for a purpose, and the more effort put into data collection, the more likely people are to expect dividends.
Data are part of both the Old World of automated data processing and the Brave New World of heuristic data techniques such as Machine Learning, Big Data and Artificial Intelligence. Data literacy and critical thinking are becoming new, important cultural techniques. However, not everyone wants to become a data expert, and in a society based on the division of labor, we should accept this and hold computer scientists and companies with data-based business models more accountable, for example by demanding that data-based business models not be subject to any secrecy obligation and that the data-processing systems be precisely labeled.
However, I would also argue that we need a general data literacy for all people to maintain informational sovereignty; what was true 30 years ago has now become even more vital – there is no such thing as harmless data. Identifying inequities or biases in data-driven algorithmic systems are the first step towards our common digital future: Once abuse of informational power becomes visible, it can (and should) be finally addressed.
Everything starts with the will to understand in order to be able to use the power of data accordingly for the benefit of the general public or the common good. As international policy experts, researchers, and scholars, we are aware of the special responsibility that technological and scientific progress has on the human mind, and we are therefore committed to regaining informational sovereignty as a networked society. This text is intended to contribute to this endeavor.
Acknowledgements
Like all texts of mine published in recent years, this one was written after inspiring discussions with colleagues and friends from the Weizenbaum Institute for the Networked Society Berlin and the German Informatics Society. Some of the basic ideas have already been published in German, and I keep using favorite phrases and examples. The example with the petals, however, is new, and I will be glad to receive feedback from any reader who has checked this empirically with first-hand data!
Literature
Bernoulli 1841: Bernoulli, Christoph (1841): Handbuch der Populationistik. Stettin.
BVerfG (Bundesverfassungsgericht) (1983): Volkzählungsurteil vom 15.12.1983 — 1 BvR 209/83, 1 BvR 269/83, 1 BvR 362/83, 1 BvR 420/83, 1 BvR 440/83, 1 BvR 484/83.
Hamm et al. 2021: Hamm, Andrea, Yuya Shibuya, Stefan Ullrich, und Teresa Cerratto Pargman. “What Makes Civic Tech Initiatives To Last Over Time? Dissecting Two Global Cases.” In Proceedings of CHI Conference on Human Factors in Computing Systems (CHI ’21). Yokohama, Japan: ACM New York, NY, USA, 2021. https://doi.org/10.1145/3411764.3445667.
Kleist 1878: Kleist, Heinrich von, und Vera F. Birkenbihl. Über die allmählige Verfertigung der Gedanken beim Reden. Dielmann, 1999.
Knaut 2017: Knaut, Andrea (2017): Fehler von Fingerabdruckerkennungssystemen Im Kontext. Disssertation an der Humboldt-Universität zu Berlin. https://edoc.hu-berlin.de/handle/18452/19001 (1.4.2021)
Leibniz 1685: Leibniz, Gottfried Wilhelm (1685): Entwurf gewisser Staatstafeln. In: Politische Schriften I, edited by Hans Heinz Holz, Frankfurt am Main, 1966, S. 80–89.
Michie 1961: Michie, Donald (1961): Trial and Error. In: Barnett, S.A., & McLaren, A.: Science Survey, Part 2, 129–145. Harmondsworth.
Mitchell 1997: Mitchell, Tom M. Machine Learning. McGraw-Hill, 1997.
Northpointe 2015: A Practicioner’s Guide to COMPAS Core. http://www.northpointeinc.com/downloads/compas/Practitioners-Guide-COMPAS-Core-_031915.pdf (15.11.2021)
Perez 2019: Perez, Caroline Criado: Invisible Women: Exposing Data Bias in a World Designed for Men. Random House, 2019.
Rosling 2006: Rosling, Hans (2006): Debunking Myths about the “Third World.” TED Talk, Monterey. https://www.gapminder.org/videos/hans-rosling-ted-2006-debunking-myths-about-the-third-world/
Ullrich 2019: Ullrich, Stefan (2019): Algorithmen, Daten und Ethik. In: Bendel, Oliver (Ed.), Handbuch Maschinenethik. Wiesbaden. S. 119-144.
Weizenbaum 1976: Weizenbaum, Joseph: Computer Power and Human Reason: From Judgment to Calculation. W. H. Freeman, 1976.
Zuboff 2019: Zuboff, Shoshana: The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of Power. New York, 2019.
This text is published as part of the German-Israeli Tech Policy Dialog Platform, a collaboration between IPPI and hbs.
The opinions expressed in this text are solely that of the author/s and do not necessarily reflect the views of IPPI and/or hbs.
Spread the word
Share this Post
Read More

ExplainerEnvironment & Sustainability, Public-Private Partnerships
The Transition to Electric Vehicles in Israel
An electric vehicle (EV) operates on electricity, unlike its counterpart, which runs on fossil fuel. Instead of an…

ExplainerEnvironment & Sustainability, Public-Private Partnerships
Transitioning to a Circular Economy: What are the Challenges?
The expected increase in world population to 9.7 billion world citizens in 2050, alongside a growing middle-class, is leading to…

CommentaryEnvironment & Sustainability
Carbon Pricing and Just Transition
Carbon Pricing and Global GHG Emissions Economically, carbon pricing is regarded as the most efficient climate change mitigation policy,…